Job Handling
The majority of workflow process in HxMap can be run on the local machine or using the distributed computing HTCondor cluster. For all time consuming HxMap processing steps, it is highly recommended to run them on HTCondor environment for production purposes.
At the end of setting the parameters for the job, a Job submission Dialog or last page of Wizard will ask for the following:
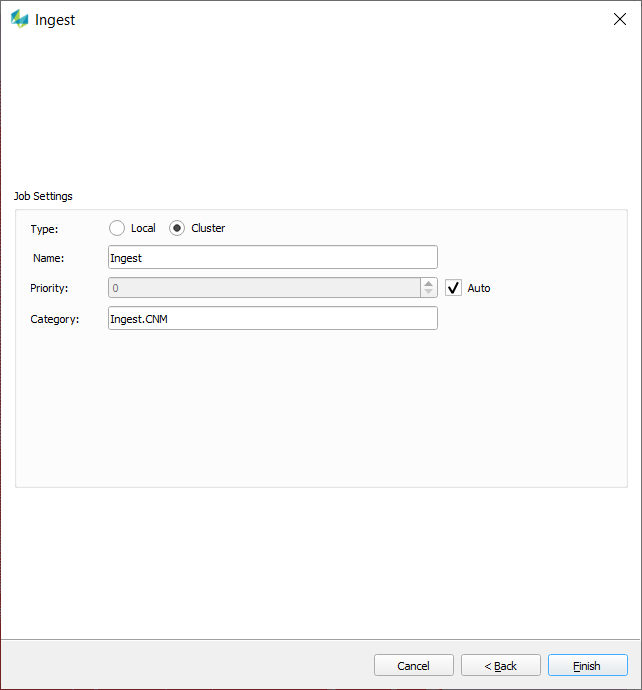
Type
Local: run Locally on the workstation
Cluster: submit to HTCondor Cluster for distributed computing
Name: free text string used to identify jobs
Priority: Integer to be used to prioritize with in the user’s list of jobs
auto: set so that a job submitted first has a higher priority to provide first in first out scheduling.
user provided: integer value provided by user, larger values denote better priority and default is “0” for no priority
Category:
free text string used to categorize jobs in the cluster according to HTCondor priority and group accounting
text will be added to the Key word “accounting_group“ in HTCondor Submit file
by default it uses the main job or product type like the one used in the Product Editor-->Filter (ORTHO, AERIAL, INFOCLOUD etc) followed by “.” separator and the Sensor System Family(as defined in the calibration section: Application Settings) at the end for HTCondor accounting to be used effectively. For example, ingest for ContentMapper will have the default of “Ingest.CNM”.
user can edit this text to pass any specific thing they want to use to prioritize things in HTCondor pool manager. For example, change the text to have expedited resource allocation “RapidMapping.Ingest.CNM” if the “RapidMapping” group hierarchy has been configured in the pool resource quotas allocation to have the highest number of resources in the pool.
When a job is run on HTCondor cluster, please use the Job monitoring capabilities of the cluster to find out when the submitted job finishes. When processing locally, HxMap will show a dialog when all processing jobs have finished.
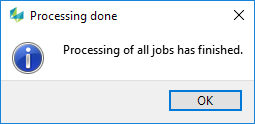
Regardless of local or cluster run, once the processing finishes the majority of the workflow steps require that the data loaded in the data source tree be refreshed before continuing with the next processing step.
Each Cluster Job run is isolated from others by having all its related file in a unique directory which allows for deployment of multiple HxMap versions in the same submitter machine:
All files related to the run (*.rsp, *.sub, *.dag, *.err, *.out etc) will be found in: <HxTemp>/<HxMap-Version>/HXMAP_LOG_PREFIX/